A number of survey based studies, e.g. Understanding Society, English Longitudinal Study of Ageing, now collect biological samples from the blood, hair, saliva, teeth, nails and urine of their respondents. However, not all survey respondents are willing or able to provide such samples. For example, in wave 2 of the English Longitudinal Study of Ageing, of 8,780 eligible participants only 7,666 (87%) took part in the nurse visit, and a valid blood biomarker was obtained for only 5,899 participants (67%). In wave 2 of Understanding Society, of 35,937 eligible participants only 13,107 (36.5 %) provided a valid blood biomarker, but this low percentage is also caused by sub-sampling participants for the nurse visit.
Given the high proportion of missing biomarker data, it becomes particularly important to investigate the reasons for missing biomarker data (missingness mechanisms) and to account for the missing data in statistical analysis, for example through inverse propensity weighting, multiple imputation and selection models.
One of the strengths of survey data is the detailed information on those participants who take part in either the interview or questionnaire based components. Usefully, it is now standard for assessors (usually nurses) to record reasons for missing biological samples. These data on reasons inform analyses of biosocial data as we illustrate here. We use data from wave 6 of the English Longitudinal Study of Ageing (ELSA). At wave 6, hair samples were collected for the first time. From these hair samples, hair analytes such as cortisol were processed. Hair cortisol is an integrated measure of Hypothalamic- Pituitary-Axis (HPA) axis activity, with higher levels indicating higher physiological stress responses. Around 2 cm of hair was collected, which is indicative of stress levels over the last 2-3 months. There are considerable amounts of missing hair cortisol data. Of 7,419 ELSA participants in the nurse data collection, there were only 2,558 participants with hair cortisol data. This is partly because some people were ineligible for the data collection (having less than 2 cm of hair). Others refused to give hair samples, mainly for reasons related to appearance. And funding constraints meant that only a subset of the hair samples could be processed to produce hair cortisol data.
As baldness predominantly affects men, we may expect gender to be associated with having hair cortisol data. Furthermore, given the association of ageing with hair loss, we may expect younger participants to be more likely to have hair cortisol data. Also, given the importance of appearance to some participants, it is likely that having a negative self-image is linked to missing hair cortisol data. As the ELSA survey asks detailed questions related to depressive symptoms (the CESD questionnaire), we can examine to what extent these survey questions predict having hair cortisol data. As stress and depression are interlinked, depressive symptoms may predict both missing hair cortisol data as well as higher levels of hair cortisol.
We explored these predictors of having hair cortisol data in the ELSA dataset. Overall, there was an pattern of men being less likely to have hair cortisol data compared to women, except in the youngest age group (50-59) where both men and women had low probabilities (around 0.2) of having hair cortisol data. We also saw that depressed participants (who scored 4 or more on the CESD questionnaire) had a 7% lower probability of having hair cortisol data compared to non-depressed participants.
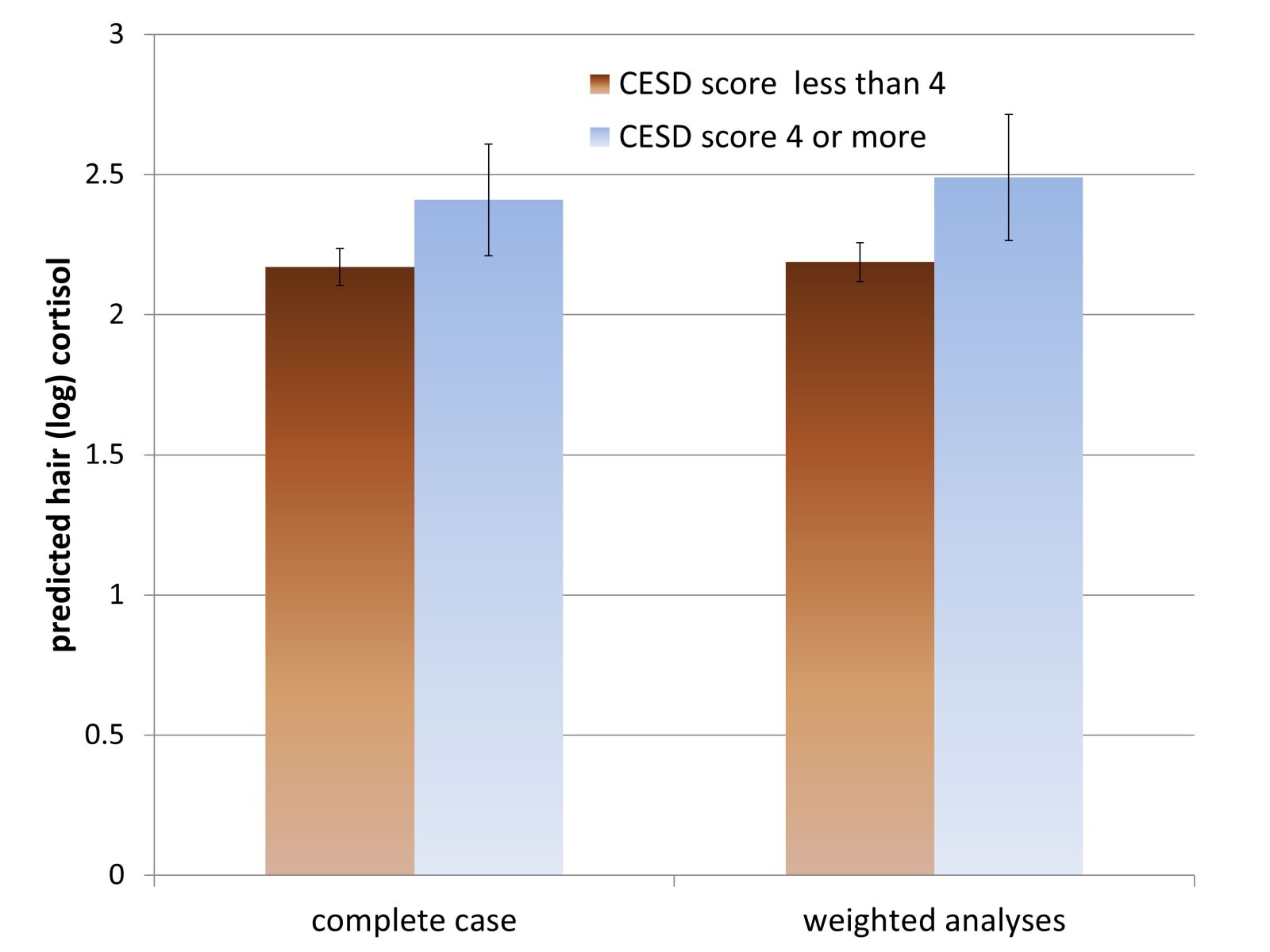
We used these three variables (depressive symptoms and the interaction between age and gender) in a logistic regression model to predict missingness and derived weights for missing hair cortisol data based on inverse probability weights from this response model. We then applied these weights to the regression model predicting (log) cortisol with depression as the explanatory variable and compared these estimates to the complete case analyses where no weights are used, but accounting for the design of the survey in both cases with respect to clustering and stratification. We see that although both the complete case and weighted analyses show similar patterns, the association of depression with (log) cortisol is stronger in the weighted analyses. When the log cortisol estimates are exponentiated, there is a difference of 2.38 pg/mg in cortisol estimates from the complete case vs weighted analyses. This suggests that the association between depression and cortisol is under-estimated in the complete case analysis, possibly because there are fewer depressed people who are willing to give a hair sample.
There are many caveats to this analysis. The model of missingness would normally include many more predictors and it also does not take into account the other complexities of missing ELSA data at wave 6 such as survey weights for the nurse visit. But the main point is the richness of the survey data which allows us to discover factors that are both correlated with the missingness mechanism as well as our outcome of interest. Our inference based on complete case analyses may be biased if we don’t take account of such factors. Researchers using biosocial datasets should investigate the reasons behind missing biological data using the rich survey data to discover the missingness mechanisms and incorporate such information in their methods to deal with missing data.